



Neural network (Source: https://news.mit.edu/2022/neural-networks-brain-function-1102)
The development of neural networks is an active subject of study, as academics and businesses attempt to find more efficient ways to handle complicated problems using machine learning.
Initially employed for simple tasks such as spam detection, neural networks have now evolved to more complicated jobs such as visual search engines, recommendation systems, chatbots, and the medical industry. Indeed, neural networks are utilised for anything from Netflix television suggestions to text generation.
Neural networks have evolved over time from simple structures capable of handling limited input to huge architectures with millions of parameters trained on massive datasets. A neural network lies at the heart of today's cutting-edge models, from YOLO to GPT.
What is a Neural Network?
A neural network is a structure made up of elements known as "neurons" that are stacked in layers. Neurons employ mathematical functions to determine whether or not to "fire" and transfer information to the next layer of neurons. The architecture is modelled after the human brain, where neurons activate and connections are formed between them. Neural networks may be used to handle complicated challenges ranging from picture generation to image recognition.
Data is fed into a neural network and processed by numerous layers of artificial neurons to create the desired output. Each neuron is made up of several components, as seen in the diagram below:

Graphical representation of the neuron is shown above. (Source: https://blogs.cornell.edu/info2040/2015/09/08/neural-networks-and-machine-learning/)
Features of a Neuron
Input
The input refers to the features that are provided into the model during the learning process. In the case of object detection, for example, the input may be an array of pixel values from an image.
Weights
Weights are used to highlight the "features" that have the greatest influence on the learning process. The more frequently a feature occurs in a successful prediction generated by a network, the more weight is assigned to the neuron(s) that represent that information. Scalar multiplication of the input value with the weight matrix yields the weights. A negative phrase, for example, would have a greater impact on the output of a sentiment analysis model charged with recognising negative words than a pair of neutral terms.
Activation Function
An activation function's primary job is to convert a node's summed weighted input into an output value that may be passed on to the next hidden layer or utilised as the final output.
Activation functions decide whether or not to activate a neuron based on its input to the network. These functions employ mathematical procedures to determine whether or not the input is relevant for prediction. If an input is considered significant, the function "activates" the neuron.
The majority of activation functions are non-linear. This enables neural networks to "learn" characteristics about a dataset (for example, how distinct pixels in a picture make up a feature). Neural networks could only learn linear and affine functions without non-linear activation functions. Why is this a problem? It's a problem since linear and affine functions can't represent the complex and non-linear patterns seen in real-world data.
Bias
The properties of a neuron that are added to the weighted sum of inputs before going through the activation function are referred to as bias. Bias is often expressed as a scalar number and is learnt with the weights during the neural network training process.
The bias term can alter a neuron's output by moving the activation function to the left or right, hence altering the range of output values and the number of neurons that fire. This can have a substantial influence on the network's overall behaviour.
The General Structure of a Neural Network
Neural networks vary greatly. Every day, individuals in industry and academics throughout the world experiment with novel neural network configurations that address a given problem better than prior iterations. However, there are a few characteristics of a neural network that are similar across networks.
The figure below depicts the overall structure of a neural network, which includes an input layer, hidden layers, and output layers:

General structure of a neural network (Source: https://journals.sagepub.com/doi/full/10.1177/00368504221079184).
Input Layer
The input layer of a neural network takes data. This content has been reduced to a structure that the network recognises after being processed from sources such as images or tabular data. This is the sole visible layer in the whole neural network architecture. Without any calculation, raw data is passed through the input layer.
Hidden Layer
Deep learning is built on hidden layers (as seen in the figure above). They are the intermediary layers that carry out computations and extract data characteristics. There might be several interconnected hidden layers, each responsible for recognising distinct data characteristics. In image processing, for example, early hidden layers identify high-level elements such as edges, forms, or limits, whereas later layers do more sophisticated tasks such as recognising full objects such as automobiles, buildings, or people.
Output Layer
The output layer takes input from the hidden layers that came before it and delivers a final prediction based on the model's learnt knowledge. The output layer in classification/regression models is typically composed of a single node. However, the number might vary depending on the sort of problem being handled and how the model was built.
Neural Networks Architectures
The architecture of the network, which dictates how the network processes and interprets input, is a critical aspect in the effectiveness of neural networks.
Understanding the various designs, as well as their strengths and limitations, is critical for picking the best network for a specific job, obtaining peak performance, and intuitively understanding how we arrived at the present neural networks.
The Perceptron
The most fundamental neural network architecture is a perceptron. Perceptrons take several inputs, perform mathematical operations on them, and produce an output.
The perceptron receives a vector of real-value inputs, linearly combines each input with its appropriate weight, sums the weighted inputs, and runs the result via an activation function. Perceptron units can be linked together to form more complicated Artificial Neural Network topologies.
Feed-Forward Networks
A perceptron is a model of a single neuron's behaviour. A multi-layer neural network is formed when many perceptrons are placed in a sequence and organised into layers.
Information travels from left to right in this design, beginning with the input layer, travelling through numerous hidden levels, and eventually reaching the output layer. Because information does not loop back between concealed levels, this network is known as a feed-forward network. The subsequent layers do not offer input to the preceding levels; learning is one-way. The perceptron's learning mechanism is unchanged.
Residual Networks (ResNet)
Now that you've learned a little bit about feed-forward networks, you might be wondering how to calculate the number of layers in a neural network architecture.
A widespread fallacy is that the greater the number of hidden layers in a network, the better the learning process. This, however, is not always the case. Because of difficulties like as disappearing and ballooning gradients, neural networks with several layers can be difficult to train.
Residual Networks (ResNets) are one technique of tackling these challenges. ResNets, as opposed to typical feed-forward networks, give an additional channel for data flow, making training faster and easier.
ResNets are designed on the premise that a deep network may be built from a shallower network by replicating weights from the shallower network via identity mapping. Data from preceding tiers is "fast-forwarded" and transported forward through the network via skip connections. These connections were initially used in ResNets to aid in the solution of the vanishing gradient problem.
Recurrent Neural Networks (RNNs)
In circumstances when the input size is not set, traditional deep learning architecture has a fixed input size, which might be a constraint. Furthermore, these models make judgements based solely on the present input, with no regard for past inputs.
Recurrent Neural Networks (RNNs) are well-suited for dealing with data sequences as input. They are particularly good at NLP tasks like sentiment analysis and spam filters, as well as time series challenges like sales forecasting and stock market prediction. RNNs can "remember" prior inputs and utilise that knowledge to make future predictions.

Architecture of single RNN cell (Source: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks)
Sequential data is supplied into RNN as input. With each new input sequence, the network's internal hidden state is updated. The model receives this internal hidden state and generates an output at each timestamp. The network gets a new input sequence at each timestamp and changes its internal hidden state depending on both the new input and its existing hidden state. This updated hidden state is then utilised to provide an output, which might be a prediction, classification, or other type of decision.
The timestamp relates to the order of presentation of the input sequences to the network. The timestamp can correlate to the location of a word in a phrase in some applications, such as natural language processing. The timestamp can equate to a point in time in various applications, such as time series forecasting.
At each timestamp, the internal hidden state is fed back to the model, which implies that the hidden state of the previous timestep is transmitted to the current timestep to generate a prediction or decision. This enables the network to keep a "memory" of previous inputs and utilise that data to guide its present output.
The Long Short Term Memory Network (LSTM)
Traditional RNNs make predictions only based on the previous timestamp and have a limited short-term memory. It does not take into account information from further back in time. To enhance this, we may include the idea of "memory" into the recurrent neural network structure.
We can do this by including gates into the network structure. These gates enable the network to recall data from past timestamps, allowing it to have a longer-term memory.

Representation of an LSTM cell (Source: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks)
- Cell state (Ct): The cell state, denoted as Ct, is associated with the network's long-term memory.
- Forget gate: The forget gate removes obsolete information from the cell state. It requires two inputs: the current timestamp input (Xt) and the prior cell state (h_t-1), which are multiplied by their respective weight matrices before bias is applied. The output is sent via an activation function, which generates a binary value that decides whether the information is retained or destroyed.
- Input gate: The input gate determines which fresh data should be added to the cell state. It works similarly to the forget gate in that it uses the current timestamp input and the prior cell state, but it uses a different set of weights for multiplication.
- Output gate: The output gate's function is to extract useful information from the current cell state and deliver it as an output.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are feed-forward neural networks that are extensively used for image analysis, natural language processing, and other difficult image classification challenges.
CNNs are built on hidden layers called as convolutional layers, which serve as the network's foundation. In picture data, features include microscopic details like edges, borders, forms, textures, objects, circles, and so on.
A CNN's convolutional layers use filters to recognise these patterns in image input, with lower layers concentrating on simpler features and deeper layers detecting more complex features and objects. Later layers, for example, may recognise specific items such as eyes or ears, and eventually animals such as horses and elephants.

The architecture of a Convolutional Neural Network CNN (Source: https://nafizshahriar.medium.com/what-is-convolutional-neural-network-cnn-deep-learning-b3921bdd82d5)
The number of filters must be supplied when adding a convolutional layer to a network. A filter may be thought of as a tiny matrix with a fixed number of rows and columns. The values in this feature matrix are generated at random. When the convolutional layer gets input data pixel values, it convolves across each patch of the input matrix. The convolutional layer output is often sent via a ReLU activation function, which introduces nonlinearity into the model by replacing all negative values with zero.
Pooling is an important stage in CNNs since it decreases computation while also making the model more resistant to distortions and variances. A fully connected dense neural network would then generate predictions depending on the specific use case using a flattened feature matrix.
Generative Adversarial Network (GAN)
Generative modelling is an unsupervised learning subcategory in which fresh or synthetic data is generated based on patterns observed in a collection of input data. Generative Adversarial Networks (GANs) are a form of generative model that can learn patterns in input data to produce wholly new synthetic data. GANs are an active and popular field of AI research.

Architecture of a Generative Adversarial Network (Source: https://www.researchgate.net/figure/Generative-adversarial-network-architecture_fig2_337930026)
GANs are made up of two parts: a generator and a discriminator that compete with one another. The generator is in charge of producing synthetic data based on the properties it discovered during the training phase. It takes in random data and generates an image after applying multiple modifications. The discriminator serves as a critic, has a general awareness of the issue domain, and can recognise produced images.
The generator produces images, and the discriminator determines whether they are fake or true. The discriminator produces a probabilistic prediction between 0 and 1, with 1 being an authentic image and 0 representing a false image. The generator continues to generate samples, while the discriminator tries to differentiate between samples from the training set and samples generated by the generator. The discriminator provides input to the generator in order for it to enhance its performance.
When the discriminator distinguishes between real and false samples, its settings do not need to be altered. When the generator fails to create images that can mislead the discriminator, it is penalised. However, if it is successful in convincing the discriminator that the created image is real, it signals that the generator's training is developing well. The generator's ultimate goal is to deceive the discriminator, whereas the discriminator's purpose is to enhance its accuracy.
GANs are utilised in a variety of applications, including video frame prediction, text-to-image creation, picture-to-image translation, image denoising, and more.
Transformers
Training RNNs and LSTMs may be time-consuming and inefficient, especially when dealing with vast amounts of sequencing data and the vanishing gradients problem. One difficulty is that data must be fed in sequentially, which does not fully utilise GPUs.
Transformers, which use an encoder-decoder structure and allow input data to be transferred in parallel, were invented to overcome this issue. Unlike RNNs, which feed input one word at a time, Transformers do not use timestamps for input; the full phrase is sent in at once, and embeddings for all words are formed concurrently.
For instance, in language processing, Transformers enable the processing of the full input phrase at once, rather than one word at a time like RNNs do.
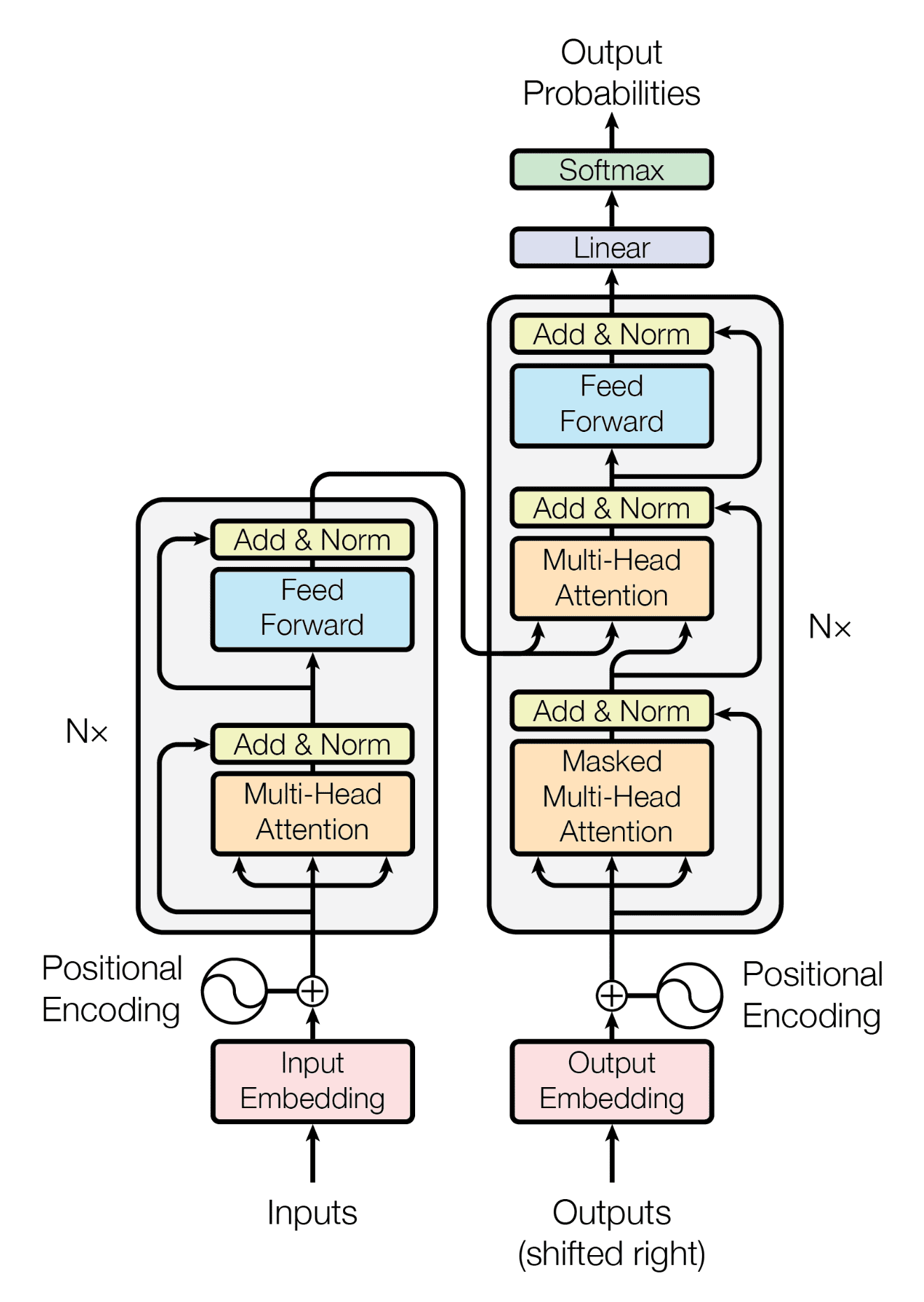
Transformer architecture.
Computers work with numbers and vectors rather than words. They employ a technique called word embedding to represent words, which maps each word to a point in a vector space called the embedding space. To map a word to a vector, a pre-trained embedding space is used. However, the same term might have distinct meanings in different circumstances.
Embeddings capture a word's context depending on its position inside a phrase. When Input Embeddings are used with Positional Encoding, the output embeddings contain context information. This is sent to an encoder block, which has a multi-head attention layer and a feed-forward layer. The attention layer determines which portions of the input text the model should focus on. The decoder is fed appropriate French sentence embeddings during training, which are made up of three primary components.
In transformer networks, the self-attention mechanism creates attention vectors for each word in a phrase, showing the significance of each word to all other words in the same sentence. The "encoder-decoder attention block," which evaluates the connection between each word vector, then processes these attention vectors and the encoder's vectors.
This block is in charge of translating from English to French. By replacing RNNs with Transformers, a substantial shift in architecture was implemented. Transformers, as opposed to RNNs, employ parallel computation and include a self-attention mechanism that protects critical information, reducing the difficulties associated with sequential input processing and information loss in RNNs.
GPT
GPT is a generative training language model that does not require labelled data for training. It forecasts the likelihood of a word sequence in a language. So far, there are three versions of it: GPT-1, GPT-2, and GPT-3.
The GPT-1 model is trained in two stages: unsupervised pre-training on a huge corpus of unlabeled data using the language model objective function, followed by supervised fine-tuning on a given task using task-specific data. The transformer decoder design underpins the GPT-1 concept.
GPT-2's major focus is on text generation; it employs an autoregressive technique and trains on input sequences with the goal of predicting the next token at each point in the sequence. The model is constructed using transformer blocks, with an emphasis on the attention mechanism, and has fewer dimensional parameters than BERT, but it has more transformer blocks (48 blocks) and can handle longer sequences.
GPT3's design is identical to GPT2, however it features more transformer blocks (96 blocks) and is trained on a bigger dataset. Furthermore, the sequence length of the input phrases in GPT3 is double that of GPT2, making it the biggest neural network design with the most parameters.
Conclusion
Each type of neural network architecture has its own strengths and limitations.
Feed-forward neural networks are widely used for solving simple structured data problems like classification and regression.
Recurrent neural networks are more effective in handling sequential data such as text, audio and video.
Recent studies have shown that Transformer networks, which use attention mechanisms, have surpassed RNNs in many areas, and represent the foundation of many of today's state-of-the-art models.
Learn more about SKY ENGINE AI offering
To get more information on synthetic data, tools, methods, technology check out the following resources:
- Telecommunication equipment AI-driven detection using drones
- A talk on Ray tracing for Deep Learning to generate synthetic data at GTC 2020 by Jakub Pietrzak, CTO SKY ENGINE AI (Free registration required)
- Example synthetic data videos generated in SKY ENGINE AI platform to accelerate AI models training
- Presentation on using synthetic data for building 5G network performance optimization platform
- Working example with code for synthetic data generation and AI models training for team-based sport analytics in SKY ENGINE AI platform


