


Dataset distillation by matching trajectories (Source: https://georgecazenavette.github.io/mtt-distillation/)
Deep neural networks have grown in popularity for a variety of applications ranging from recognising items in images using object detection models to creating language using GPT models. Deep learning models, on the other hand, are frequently huge and computationally costly, making them challenging to deploy on resource-constrained devices like mobile phones or embedded systems. Knowledge distillation solves this issue by condensing a huge, complicated neural network into a smaller, simpler one while retaining its performance.
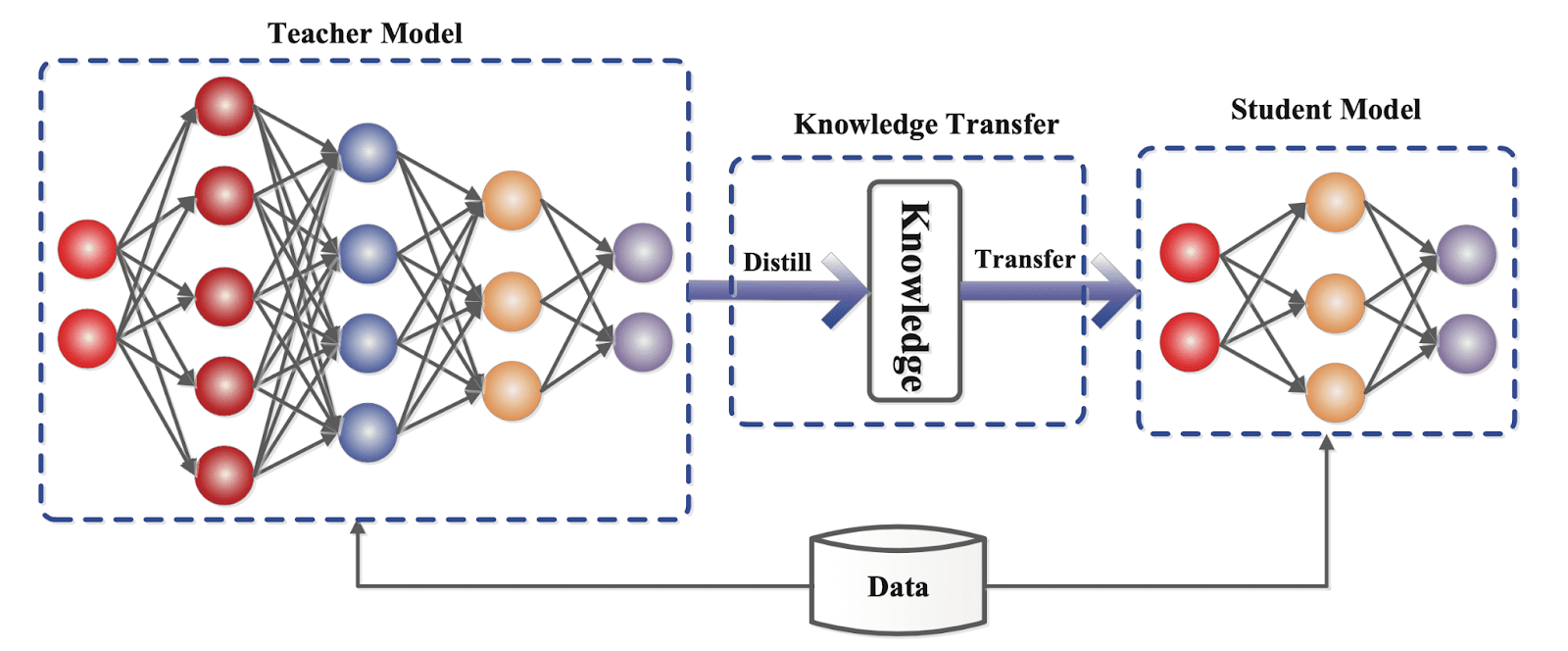
What is Knowledge Distillation?
Knowledge distillation is a technique for compressing a complicated and huge neural network into a smaller and simpler one while keeping the accuracy and performance of the final model. A smaller neural network is trained to replicate the behaviour of a bigger and more complicated "teacher" network by learning from its predictions or internal representations.
The purpose of knowledge distillation is to minimise a model's memory footprint and computational needs while maintaining its performance. Hinton et al. were the first to propose knowledge distillation in 2015. Since then, the concept has gotten a lot of interest in the scholarly community.
The notion of knowledge distillation is founded on the fact that a large neural network learns to collect meaningful and usable representations of input in addition to making accurate predictions. These representations are learnt by the neural network's hidden layers and may be viewed as "knowledge" obtained by the network throughout the training phase.
The "knowledge" gathered by the teacher network is transmitted to the student network via supervised learning in the context of knowledge distillation. On a set of training examples, the student network is trained to minimise the gap between its predictions and those of the instructor network.
The underlying assumption is that the teacher network's predictions are based on a rich and sophisticated representation of the input data, which the student network may learn to mimic through the distillation process.
Stanford's Alpaca is a contemporary example of knowledge distillation in action. This LLaMA-tuned model gathered information from 52,000 instructions supplied to OpenAI's text-davinci-003 model. The Alpaca model "behaves qualitatively similarly to OpenAI's text-davinci-003, while being surprisingly small and easy/cheap to reproduce (600$)," according to Stanford.
What is the Process of Knowledge Distillation?
Data distillation approaches are categorised into three major types depending on distinct optimisation objectives: performance matching, parameter matching, and distribution matching.
Each category includes a number of ways. For each category, we will offer a description of two ways. The figure below depicts the categories of data distillation.
Training the instructor network and training the student network are the two key processes in knowledge distillation.
The first phase involves training a large and complicated neural network, known as the teacher network, using a dataset using a typical training process. Once trained, the teacher network is used to create "soft" labels for the training data, which are probability distributions over the classes rather than binary labels. These soft labels are more informative than hard labels because they represent the uncertainty and ambiguity in the instructor network's predictions.
The second phase involves training a smaller neural network, known as the student network, on the same dataset using the soft labels given by the teacher network. The student network is taught to minimise the discrepancy between its own predictions and the instructor network's soft labels.
The idea behind this method is that soft labels convey more information about the input data and the predictions of the teacher network than hard labels. As a result, the student network can learn to collect this additional knowledge and generalise it to new cases more effectively.
As seen here, a tiny "student" model learns to copy a big "teacher" model and exploit the teacher's experience to achieve similar or superior accuracy.
The teacher-student framework for knowledge distillation. (Source: https://arxiv.org/abs/2006.05525)
Knowledge Distillation Use Cases
One of the primary advantages of knowledge distillation is that it may drastically lower a model's memory and computational needs while retaining comparable performance to the bigger model.
This is especially relevant for applications that require models to operate on low-resource devices like mobile phones, embedded systems, or Internet of Things (IoT) devices. Knowledge distillation allows models to be implemented on these devices without affecting performance by condensing a big and complicated model into a smaller and simpler one.
Types of Knowledge Distillation
Depending on how the information is acquired from the instructor model, knowledge distillation may be classified into several forms.
In general, three forms of knowledge distillation exist, each with its own strategy of transferring knowledge from the instructor model to the student model. These are some examples:
- Response-based distillation;
- Feature-based distillation, and;
- Relation-based distillation.

The different kinds of knowledge in a teacher model. (Source: https://arxiv.org/abs/2006.05525)
Response-based
The student model learns to imitate the teacher model's predictions by minimising the gap between projected outputs in response-based knowledge distillation. During the distillation process, the teacher model provides soft labels for each input example, which are probability distributions over the classes. The student model is then trained to predict the same soft labels as the instructor model by minimising the difference between their projected outputs.
Response-based distillation is frequently employed in image classification, natural language processing, and speech recognition, among other machine learning fields.
Response-based knowledge distillation is especially effective when the teacher model has a large number of output classes and training a student model from scratch would be computationally costly. Using response-based knowledge distillation, the student model may learn to emulate the behaviour of the teacher model without having to understand the intricate decision boundaries that differentiate all output classes.
One of the primary benefits of response-based knowledge distillation is its simplicity of implementation. Because this method simply requires the predictions of the instructor model and the appropriate soft labels, it may be used to a broad range of models and datasets.
Furthermore, by condensing a model into a smaller and simpler one, response-based distillation can drastically lower the processing needs of running it.
Response-based knowledge distillation, on the other hand, has limits. For example, this method simply transmits information relating to the teacher model's projected outputs and does not capture the teacher model's internal representations. As a result, it may not be appropriate for situations requiring more complicated decision-making or feature extraction.

Response-based knowledge distillation. (Source: https://www.researchgate.net/publication/356869657_Situational_Awareness_and_Problems_of_Its_Formation_in_the_Tasks_of_UAV_Behavior_Control)
Feature-based
The student model is taught to duplicate the internal representations or features learnt by the teacher model in feature-based knowledge distillation. The internal representations of the instructor model are taken from one or more intermediary layers of the model and utilised as goals for the student model.
The instructor model is initially trained on the training data during the distillation process to acquire the task-specific properties that are relevant to the activity at hand. The student model is then taught to learn the same characteristics as the teacher model by minimising the distance between the features learnt by the two models. This is commonly accomplished by employing a loss function, such as the mean squared error or the Kullback-Leibler divergence, that assesses the distance between the representations learnt by the teacher and student models.
One of the primary benefits of feature-based knowledge distillation is that it can assist the student model in learning more informative and robust representations than it could learn from beginning. This is due to the fact that the teacher model has already learnt the most significant and useful aspects from the data, which can then be communicated to the student model via the distillation process. Furthermore, feature-based knowledge distillation is a versatile approach that may be used to a wide range of activities and models.
However, there are several drawbacks to feature-based knowledge distillation. Because it involves extracting the internal representations from the instructor model at each iteration, this method can be more computationally costly than other forms of knowledge distillation. Furthermore, a feature-based method may not be appropriate for situations in which the internal representations of the instructor model are not transferrable or meaningful to the student model.

Feature-based knowledge distillation. (Source: https://www.researchgate.net/publication/342094012_Knowledge_Distillation_A_Survey)
Relation-based Knowledge Distillation
A student model is trained in relation-based distillation to learn a link between the input instances and the output labels. Relation-based distillation, as opposed to feature-based distillation, focuses on transmitting the underlying connections between the inputs and outputs.
The teacher model first creates a collection of relationship matrices or tensors that represent the relationships between the input instances and the output labels. The student model is then trained to learn the same connection matrices or tensors as the teacher model by minimising a loss function that assesses the difference between the predicted relationship matrices or tensors and those generated by the teacher model.
One of the primary benefits of relation-based knowledge distillation is that it can assist the student model in learning a more robust and generalizable link between the input instances and output labels than it could learn from beginning. This is due to the fact that the teacher model has already learnt the most relevant links between the data's inputs and outputs, which can be communicated to the student model via the distillation process.
However, constructing the association matrices or tensors can be computationally costly, especially for big datasets. Furthermore, a relation-based method may not be appropriate for jobs in which the links between the input cases and the output labels are poorly defined or difficult to express into a collection of matrices or tensors.

Relation-based knowledge distillation. (Source: https://www.researchgate.net/publication/342094012_Knowledge_Distillation_A_Survey)
Distillation Knowledge Training Methods
There are three main methods for training student and instructor models: Offline, online, and self distillation are all options. The classification of a distillation training technique is determined by whether the teacher model is adjusted concurrently with the student model, as seen in the image below:

Types of Knowledge Distillation training schemes. (Source: https://arxiv.org/abs/2006.05525)
Offline Distillation
Offline Distillation is a prominent method of knowledge distillation in which the teacher network is trained and then frozen. During student network training, the instructor model remains fixed and is not changed. This strategy has been employed in numerous earlier knowledge distillation approaches, including the foundational study by Hinton et al.
The primary focus of this field's research has been on improving the information transmission process in offline distillation, with little attention paid to the design of the teacher network architecture. This method has allowed information to be transferred from pre-trained and high-performing instructor models to student models, enhancing overall model performance.
Online Distillation
Online knowledge distillation, also known as dynamic or continuous distillation, is a method of sequentially or online transferring knowledge from a bigger model to a smaller one.
The instructor model is continually updated with fresh data in this manner, and the student model is changed to reflect this new knowledge. The instructor model and the student model are both taught concurrently throughout the online knowledge distillation process. As fresh data becomes available, the teacher model is constantly updated, and the student model learns from the instructor's output. The aim is for the student model to learn in real-time from the teacher model's changes, allowing the student model to constantly improve its performance.
Online knowledge distillation often incorporates a feedback loop in which the output of the teacher model is used to update the student model and the output of the student model is used to offer feedback to the teacher model. Feedback is often provided in the form of an error signal, which reflects how well the student model performs in comparison to the instructor model. This input is then used by the teaching model to update its parameters and provide new predictions.
The capacity to handle non-stationary or flowing data is one of the key advantages of online knowledge distillation. This is especially beneficial in applications like natural language processing, where the distribution of input data changes over time. Online knowledge distillation allows the models to adapt to shifting data distributions by updating the instructor and student models in real-time.
Self Distillation
Offline and Online Distillation, the traditional way of information distillation, encounter two major obstacles. First, the correctness of the student model is greatly impacted by the instructor model selected. The most accurate teacher is not always the greatest selection for distillation. Second, student models frequently lack the accuracy of their professors, resulting in accuracy loss during inference.
To overcome these concerns, the Self Distillation approach makes use of the same network as both the teacher and the learner. This method entails linking attention-based shallow classifiers at various depths to the neural network's intermediate layers. The deeper classifiers serve as teacher models during training, guiding the training of the student models using a divergence metric-based loss on the outputs and an L2 loss on the feature maps. The additional shallow classifiers are removed during inference.
Distillation Knowledge Algorithms
Adversarial Distillation
Adversarial distillation improves the performance of student models through adversarial training. In this strategy, a student model is trained to replicate the output of the teacher model by creating synthetic data that is difficult for the teacher model to accurately categorise.
The adversarial distillation method is divided into two training steps. The instructor model is trained on the training set in the first stage to get the ground truth labels. The student model is trained on both the training set and synthetic data generated by an adversarial network in the second step.
The adversarial network is taught to create data that are difficult for the teacher model to correctly identify, and the student model is trained to correctly categorise these examples. The adversarial network creates synthetic data during training by introducing minor perturbations to the actual data sets, making them difficult to categorise. After that, the student model is trained to categorise both the original and fake data. The student model learns to generalise more successfully as a result, and hence performs better on real-world data.
The adversarial distillation algorithm outperforms classic knowledge distillation algorithms in various ways. It is more resistant to adversarial assaults since the student model learns to categorise difficult-to-classify synthetic data. Adversarial distillation also enhances the student model's generalisation capabilities by forcing it to learn from difficult cases that are not present in the training set.
Multi-Teacher Distillation
Multi-teacher distillation entails training a single student model with many instructor models. The premise behind multi-teacher distillation is that by combining many sources of information, the student model may learn a more complete collection of characteristics, resulting in enhanced performance.
The multi-teacher distillation algorithm is divided into two training steps. To get their outputs, the teacher models are first trained individually on the training set. Second, the student model is trained on the same training set as the teacher models, with the outputs of the instructor models serving as objectives. During training, the student model learns from the outputs of many teacher models, each of which provides a unique viewpoint on the training set. This enables the student model to learn a broader collection of characteristics, resulting in increased performance.
Multi-teacher distillation approaches have various benefits over traditional knowledge distillation. Because several teachers give a more broad collection of viewpoints, this strategy eliminates the bias that can be generated by a single teacher model. Multi-teacher distillation further increases the student model's resilience by allowing it to learn from numerous sources of knowledge.

Multi-Teacher distillation. (Source: https://arxiv.org/abs/2006.05525)
Cross-Modal Distillation
A knowledge distillation algorithm that moves knowledge from one modality to another is known as cross-modal distillation. When data is available in one modality but not in another, this approach comes in handy. In image recognition, for example, there may be no text labels available for the images, but there may be text data describing the images. Cross-modal distillation can be employed in such circumstances to move knowledge from the text modality to the image modality.
The student model learns to map the goal modality to the output of the instructor model during training. This enables the student model to benefit from the teacher model's expertise in the source modality, enhancing its performance in the target modality.
Cross-modal distillation allows information to be transferred from one modality to another, which is important when data is available in one modality but not in another. Furthermore, cross-modal distillation increases the student model's generalisation power by allowing it to learn from a more diverse collection of data.

Cross-Modal distillation. (Source: https://arxiv.org/abs/2006.05525)
Conclusion
By transferring knowledge from big and complicated models, knowledge distillation is a strong strategy for boosting the performance of tiny models. It has been demonstrated to be useful in a variety of applications such as computer vision, natural language processing, and speech recognition.
Distillation knowledge techniques are classified into three types: offline, online, and self-distillation. These labels are issued based on whether or not the instructor model is updated during training. Each kind has benefits and disadvantages, and the decision is determined by the unique application and available resources.
Knowledge distillation algorithms include adversarial distillation, multi-teacher distillation, and cross-modal distillation, each with its own technique to transferring knowledge from instructor to student.
Overall, knowledge distillation is an effective technique for increasing the efficiency and performance of machine learning models. This is an area of active study and development with several practical applications in the realm of artificial intelligence.
Learn more about SKY ENGINE AI offering
To get more information on synthetic data, tools, methods, technology check out the following resources:
- Telecommunication equipment AI-driven detection using drones
- A talk on Ray tracing for Deep Learning to generate synthetic data at GTC 2020 by Jakub Pietrzak, CTO SKY ENGINE AI (Free registration required)
- Example synthetic data videos generated in SKY ENGINE AI platform to accelerate AI models training
- Presentation on using synthetic data for building 5G network performance optimization platform
- Working example with code for synthetic data generation and AI models training for team-based sport analytics in SKY ENGINE AI platform


