


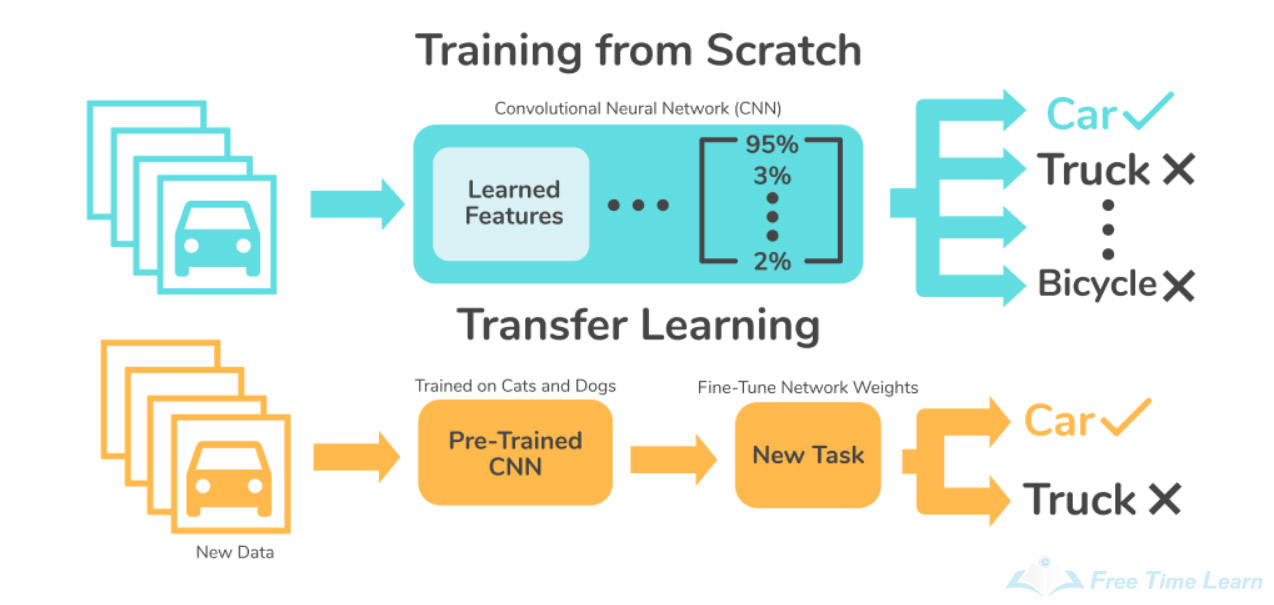
Transfer learning (Source: https://www.freetimelearning.com/software-interview-questions-and-answers.php?Explain-transfer-learning-in-the-context-of-deep-learning.&id=4184)
Assume you have an issue you want to tackle with computer vision but just a few images to base your new model on. What are your options? You might wait to collect more data, but this may be impractical if the traits you want to capture are difficult to locate (for example, uncommon animals in the wild or product flaws). In such situation, you can synthesise data using SKY ENGINE AI Synthetic Data Cloud or, in some cases, you may experiment with transfer learning.
What is transfer learning?
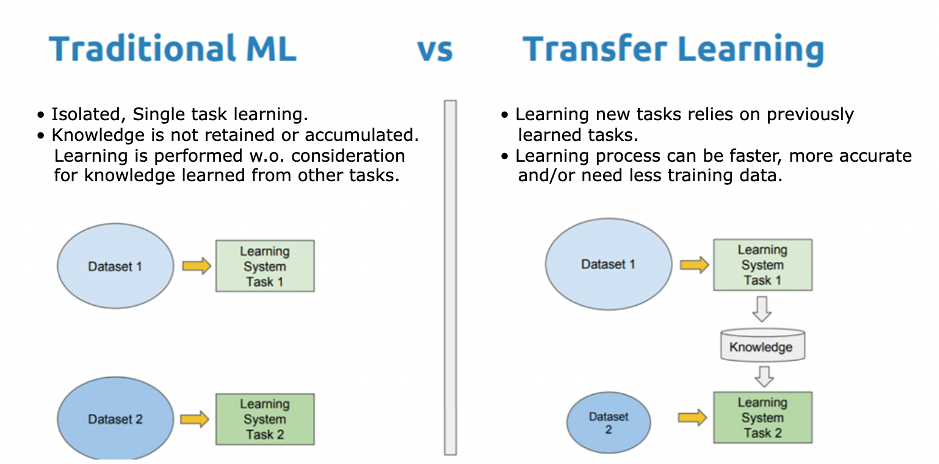
Transfer learning is a computer vision approach that involves building a new model on top of a prior one. The goal is to enable the new model to learn characteristics from the existing one, allowing the new model to be trained to its purpose faster and with less data.
The term "transfer learning" describes what this strategy entails: you transfer information from one model to another that can benefit from that knowledge. Even though the two activities are distinct, this is akin to how you may translate your understanding of painting into drawing - colour theory, aesthetic.
Example of Transfer Learning
Consider having photographs of animals obtained on an African safari. The photos in the dataset are of giraffes and elephants. Assume you want to create a model that can recognise giraffes from elephants using those photos as inputs to a model that counts animals in a certain region.
The first thought that may spring to mind is to create an image recognition model from scratch. Unfortunately, because you just took a few images, you are unlikely to attain high accuracy.
But assume you have a model that has been trained on millions of photos, for example, to discriminate between dogs and cats.
What we can do is take this already-trained model and use what it has learned to teach it to distinguish other types of animals (giraffes and elephants in our case) without having to train a model from scratch, which would require not only a large amount of data, which we do not have in this case, but also a large amount of computational complexity.
Transfer learning is the process of using the knowledge of a previously trained model to generate a new model specialised on another job.
How Transfer Learning Works
Convolutional networks are capable of extracting characteristics from high-level pictures. The initial layers of a CNN learn to recognise generic characteristics such as vertical edges, the succeeding layers learn to recognise horizontal edges, and these features may then be combined to recognise corners, circles, and so on.
These high-level characteristics are unrelated to the sort of thing we need to recognise. Computer vision models do not simply "learn" how to recognise cats, for example. Models, on the other hand, break down images into little components and understand how those small components combine to form traits associated with a certain notion.
The linear layers that accept as input the information recovered from the convolutional layers and learn to categorise in the final class recognise the entity (animals in this example).
To use transfer learning, we remove the previously trained model's linear layers (which have been trained to recognise other classes) and replace them with new ones. We retrain the new layers so that they become experts at recognising our classes of interest.
How to Use Transfer Learning
To begin using transfer learning, select a model that was trained on a big dataset to handle a comparable problem. Models from the computer vision literature, such as VGG, ResNet, and MobileNet, are commonly used. Next, remove the old classifier and output layer. Add a new classifier next. This entails modifying the architecture to handle the new task. Adding a new randomly initialised linear layer (shown by the blue block below) and another with many units corresponding to the number of classes in your dataset (represented by the pink block) is typical at this point.
The Feature Extractor layers from the pre-trained model must then be frozen. This is a critical stage. If the feature extractor layers are not frozen, your model will re-initialize them. If this happens, you will lose all of your previous knowledge. This will be the same as training the model from scratch.
Finally, the new layers must be trained. All that remains is to train the new classifier on the new dataset.
After completing the preceding steps, you will have a model that can make predictions on your dataset. You can optionally increase its performance by fine-tuning it. To adjust the pre-trained features to the new data, fine-tuning involves unfreezing sections of the pre-trained model and continuing to train it on the new dataset. To avoid overfitting, only do this step if the new dataset is big and the learning rate is modest.
When to Use Transfer Learning
Transfer Learning is beneficial when you have:
- A lack of data: Working with insufficient data will result in poor model performance. The usage of a pre-trained model aids in the creation of more accurate models. It will take less time to get a model up and running since you will not need to collect more data.
- Time constraint: Training a machine learning model can take a lengthy period. When you don't have much time, such as when creating a prototype to verify a concept, assess whether transfer learning is acceptable.
- Computational limitations: Training a machine learning model with millions of images demands a significant amount of compute. Someone has already done the legwork for you, providing you with a decent set of weights to utilise for your assignment. This decreases the amount of computation (and hence equipment) needed to train your model.
When to Avoid Using Transfer Learning
Transfer learning is ineffective when:
- A huge dataset is required: On problems requiring bigger datasets, transfer learning may not have the desired effect. The performance of the pre-trained model degrades as additional data is added. The reason for this is that as the size of the fine-tuned dataset grows, so does the model's noise. Because the pre-trained model performed well on the pre-trained dataset, it may have been stuck at the local minimum point and is unable to adjust to the new noise. If we have a huge dataset, we should consider starting from scratch and training the model to learn essential aspects from it.
- There is a domain mismatch: most of the time, transfer learning does not function if the data used to train the pre-trained model is extremely different from the data used to perform transfer learning. It is required that the two datasets predict comparable things (for example, training a defect classifier on a dataset containing similar objects that display annotated scratches and dents).
Conclusion
Transfer learning models are concerned with preserving information obtained while addressing one problem and applying it to another but related problem. Instead of beginning from scratch, numerous pre-trained models may be used as a starting point for training. Pre-trained models provide a more stable architecture while saving time and resources.
When you have a restricted amount of data, a limited amount of time, or limited compute resources, you may want to consider employing transfer learning.
Transfer learning should not be used if the data you have differs from the data used to train the pre-trained model, or if you have a huge dataset. In these two circumstances, it is preferable to train a model from the ground up.
Learn more about SKY ENGINE AI offering
To get more information on synthetic data, tools, methods, technology check out the following resources:
- Telecommunication equipment AI-driven detection using drones
- A talk on Ray tracing for Deep Learning to generate synthetic data at GTC 2020 by Jakub Pietrzak, CTO SKY ENGINE AI (Free registration required)
- Example synthetic data videos generated in SKY ENGINE AI platform to accelerate AI models training
- Presentation on using synthetic data for building 5G network performance optimization platform
- Working example with code for synthetic data generation and AI models training for team-based sport analytics in SKY ENGINE AI platform


