


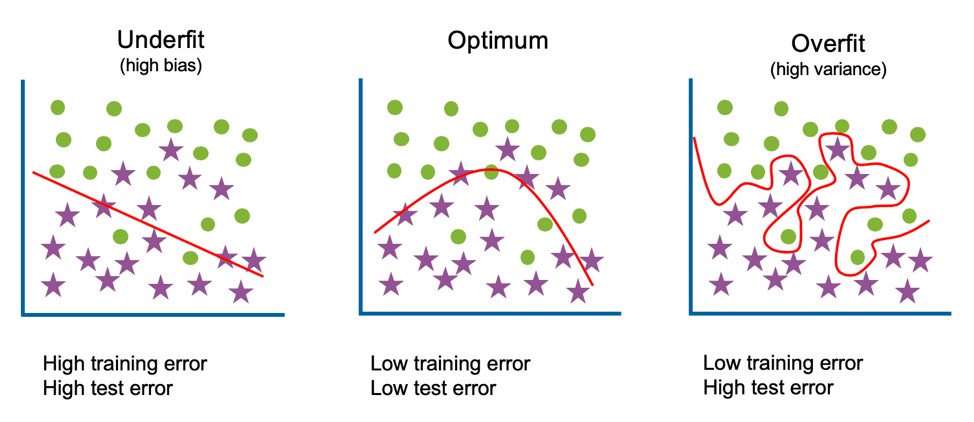
Overfitting in machine learning (Source: https://www.javatpoint.com/overfitting-in-machine-learning)
Overfitting occurs when a model fits perfectly to its training data. When the machine learning model you trained overfits to training data rather than understanding new and unknown data, the model's quality degrades.
Overfitting can arise for a variety of reasons, and addressing to these causes with various cutting-edge ways can assist.
What is Overfitting?
Overfitting occurs when a machine learning model fits perfectly to its training data. Overfitting happens when a statistical model attempts to cover all or more than the appropriate number of data points in the observed data. When overfitting happens, a model performs horribly against unobserved data.
When a model is overfit, it begins to learn too much noise and wrong values from the training data and fails to predict future observations, lowering the model's precision and accuracy.
Consider the following scenario. You have 300 images, 150 of which are lions and 150 of which are donkeys. When you train an image classifier model, it achieves 99% accuracy on the training dataset but only 45% accuracy on the test set, indicating that the model has overfitted.
It indicates that if you give the model an images of a lion from the training set sample, it properly predicts its class, however if you offer the model a random image of a lion from any other source, it fails to deliver the right result.
Overfitting has occurred in our machine learning classifier model. The classifier has learnt to recognise specific aspects of lions and donkeys, but it has not learned enough generic features to be effective on unseen photos. As a result, this model is not suitable for usage in the real world, as the findings would be unreliable.
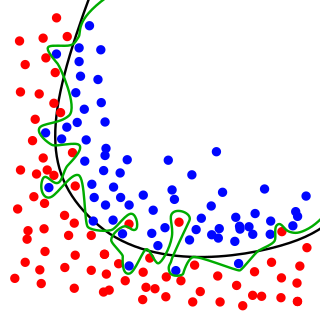
The green line represents an overfitted model and the black line represents a regularized model. While the green line best follows the training data, it is too dependent on that data and it is likely to have a higher error rate on new unseen data illustrated by black-outlined dots, compared to the black line.
Overfitting in machine-learning models can occur for a variety of reasons, including:
- When you have a model with a large variance and low bias, your training accuracy increases, but your validation accuracy declines as the number of epochs grows.
- If the dataset contains noisy data or erroneous points (trash values), the validation accuracy and variance may suffer.
- If the model is overly complex, the variance will increase but the bias will decrease. It can learn too much noise or random oscillations from the training data, reducing the model's performance on data it has never seen before.
- If the training dataset is too little, the model will only be able to explore a subset of the situations or possibilities. When presented to previously unknown data, the prediction's accuracy decreases.
Overfitting in machine learning models can be detected
Before you evaluate the data, detecting overfitting is a difficult process. The greatest thing you can do is start testing your data as soon as possible to see whether the model can perform well on the datasets with which it will operate.
The most important thing to ask is, "Does my model perform well on unseen data?" Overfitting may have occurred if your model performs badly on unseen data that is typical of the type of data you will feed your model.
However, several indicators point to your model learning too much from the training dataset and overfitting.
Make sure your datasets are in a random sequence when breaking them into train, validation, and test. This is critical. If your datasets are organised by a certain characteristic (for example, home size in square metres), your training dataset may miss out on learning about extreme situations (huge house sizes), as these will only emerge in validation and test sets.
Furthermore, the learning curve might provide you with more information than you might believe. Learning curves are representations of model learning performance over time, with the y-axis representing some learning parameter (classification accuracy or classification loss) and the x-axis representing experience (time). The validation error does not vary or grow as the number of iterations rises, although the training error does. It means that the model is overfitting, and you should cease training.
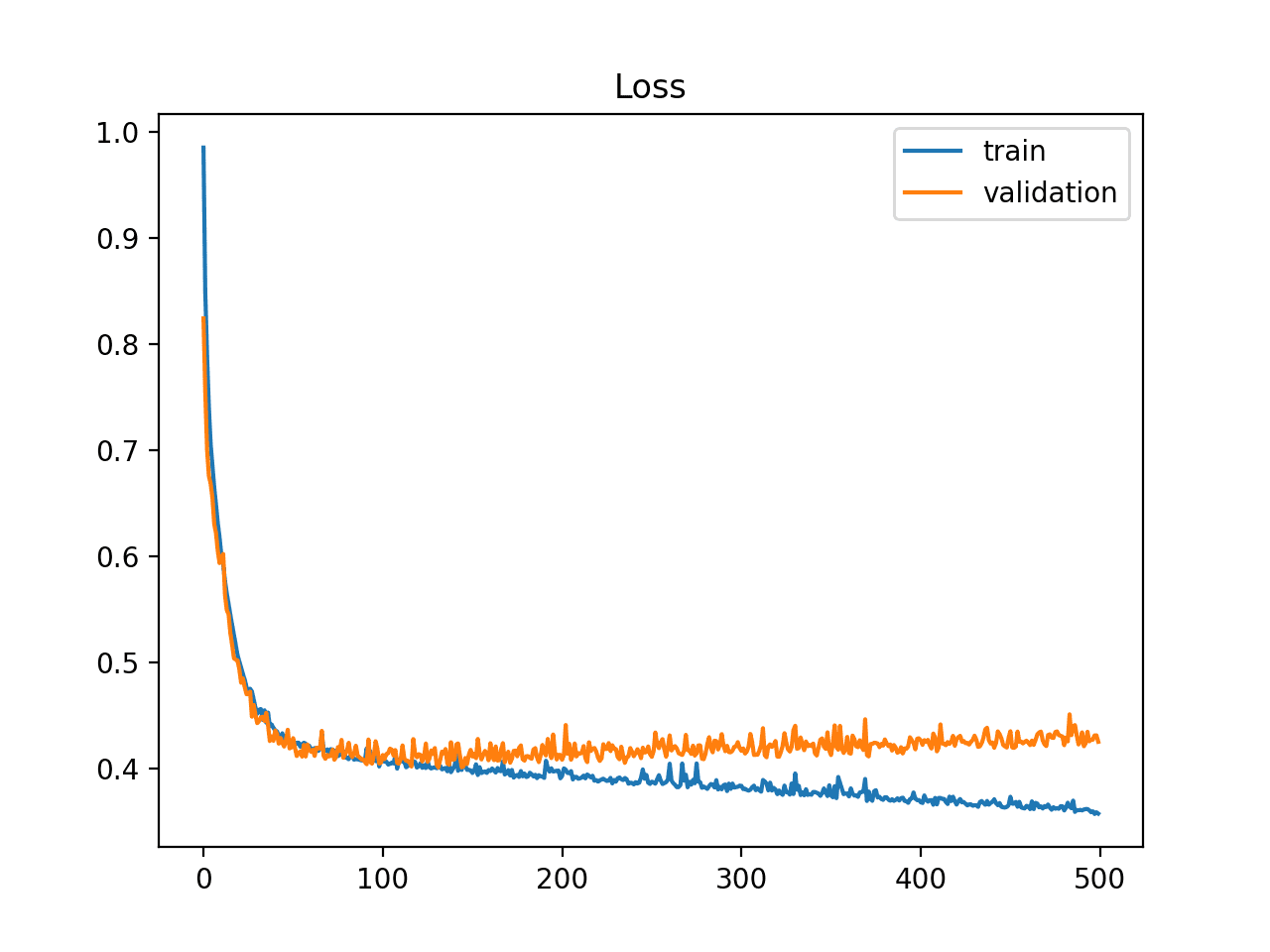
Example of Train and Validation Learning Curves Showing an Overfit Model.
How to Avoid Overfitting
Because of the quantity of factors involved, machine learning models are prone to overfitting. Understanding the strategies used to prevent overfitting is critical.
Increase the Amount of Training Data
If you have access to extra data and computational capabilities to analyse that data, adding more training data is the easiest solution to manage variation. More data allows your machine learning model to grasp more generic features rather than aspects unique to the samples in the dataset. The more basic traits a model can recognise, the less probable it is that your model will only perform well on previously viewed images.
Augment Data
Consider enhancing your data if you do not have access to extra data. With data augmentation, you may apply numerous alterations to an existing dataset to artificially expand its size. Augmentation is a frequent approach used in computer vision to enhance the sample size of data for a model.
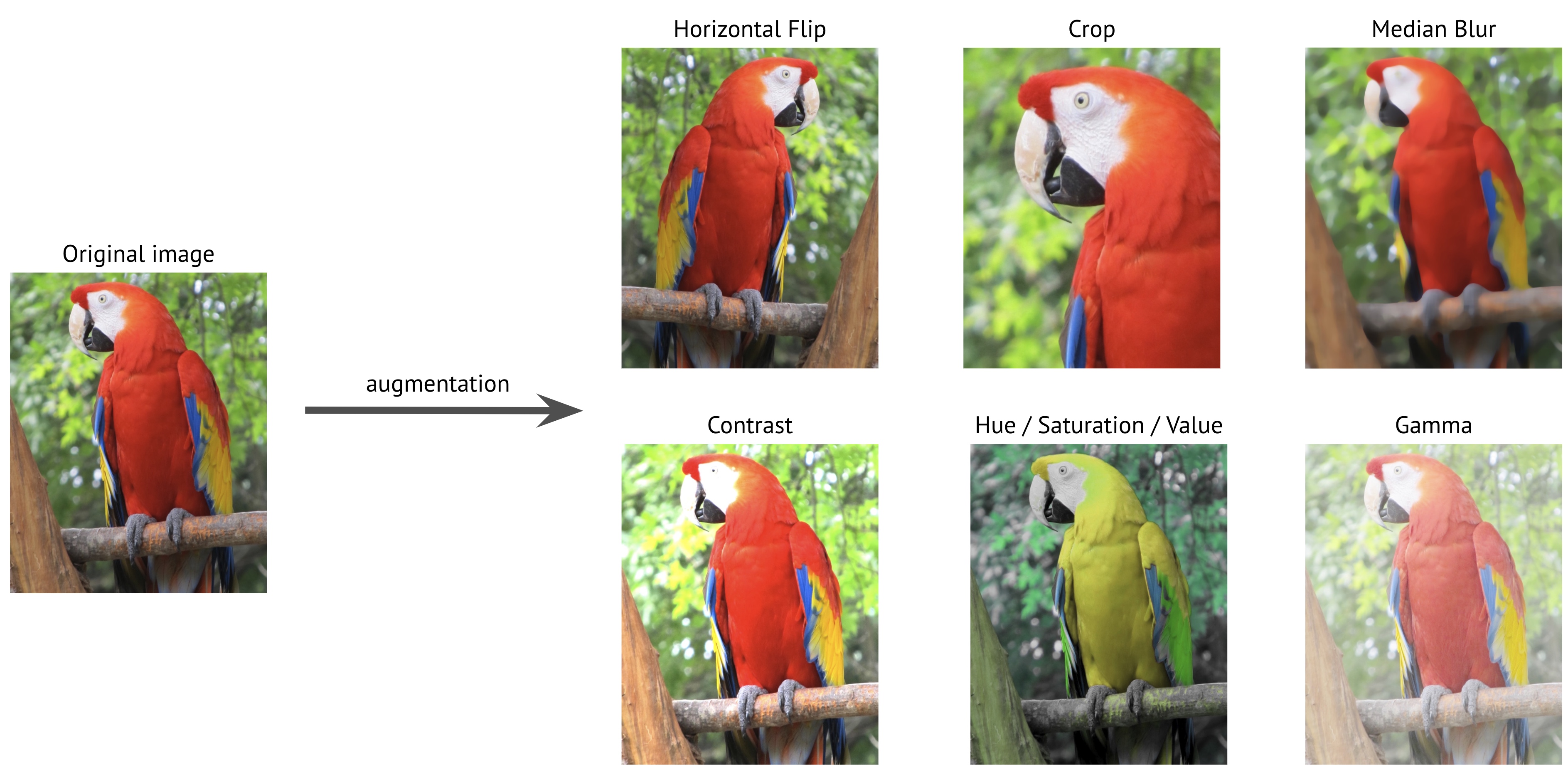
Data Augmentation examples. (Source: https://albumentations.ai/docs/introduction/image_augmentation/)
Standardization
Standardise characteristics such that they have 0 mean and unit variance. This modification is intended to accelerate the learning algorithm. Weights can change considerably without normalised inputs, resulting in overfitting and excessive variation.
Feature Selection
A typical error is to add most or all of the features offered, regardless of how many points are available for each feature. This is problematic because small sample sizes on features make it difficult for a model to grasp how a feature relates more broadly to the data in a dataset.
Consider this: does your dataset include a lot of characteristics but just a few data points for each one? If this is the case, consider only including the aspects that are absolutely necessary for training.
Cross-Validation
Cross-validation uses all of the data for training by dividing the dataset into k groups and making each group the testing set. As a testing set, repeat the method k times for each group.
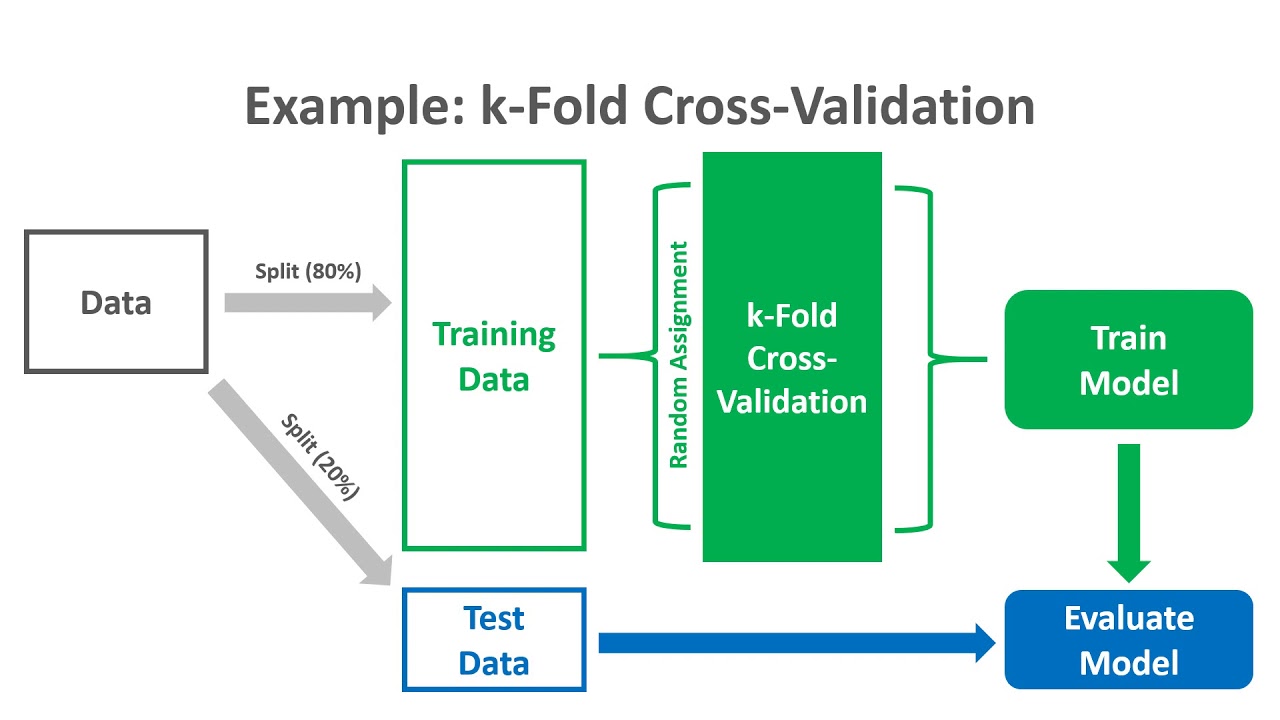
k-Fold Cross-Validation. (Source: https://www.youtube.com/watch?app=desktop&v=kituDjzXwfE)
Early Stopping
When your validation loss begins to climb, it is time to halt the training procedure. This can be accomplished by monitoring learning curves or establishing an early halting trigger.
You should experiment with various stop timings to see what works best for you. The ideal circumstance is to terminate training just before the model is expected to begin learning noise from the dataset. This may be accomplished by training numerous times and determining roughly when noise begins to impair your training. Your training graphs will help you choose the best moment to quit training.
This is tradeoff as if you stop training too soon, your model may be less performant than if you left it to train for a little longer.
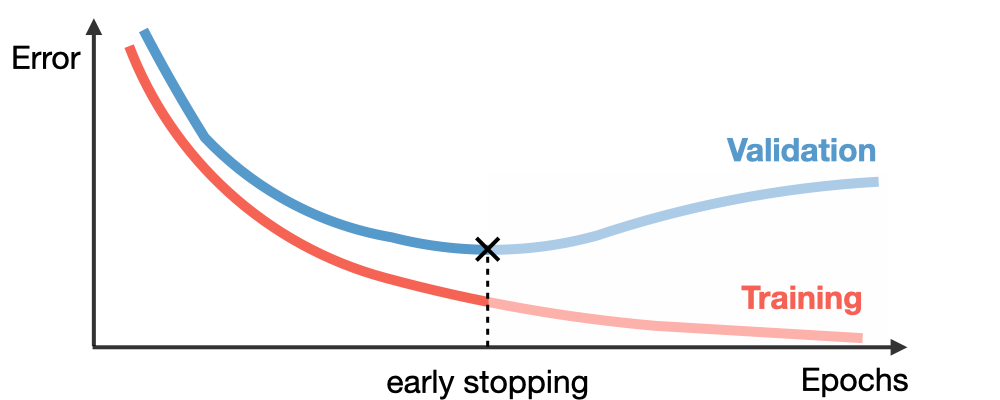
Early stopping plots.
Ensembling
In this strategy, we mix numerous strategically created models, such as classifiers or experts, to improve prediction performance. It lowers variance, reduces modelling approach bias, and lessens the likelihood of overfitting.
Regularization
This is a popular machine learning strategy that tries to reduce model complexity by greatly lowering variance while just slightly raising bias. Regularisation methods that are often employed include L1 (Lasso), L2 (Ridge), Elastic Net, Dropout, Batch Normalisation, and others.
Can Overfitting in Machine Learning Be Beneficial?
While overfitting machine learning models is usually frowned upon, it is becoming frequent when seeking to de-risk computer vision models for eventual deployment in business applications. Before devoting time and resources to a computer vision project, your organisation may want to determine whether the activity is indeed "learnable" by a model.
This may be performed by building an overfit model. After acquiring images in which you are just interested in recognising a fraction of the items that show, you will almost certainly end up filling your model with training and validation images that lack structural variety. As a result of being optimised for detection of the labelled items you highlighted in the training images, your model will overfit to that environment.
A fully de-risked project as a learnable work indicates that we have a feasible computer vision project for deployment in our organisation. Whether it's for worker safety, defect detection, document parsing, object tracking, broadcasting experiences, gaming, augmented reality apps, or anything else, overfitting is sometimes the proof we need to show vision is a viable solution to a problem.
Conclusion
Overfitting is a perennial issue in the field of machine learning. It is difficult to understand the typical causes and how to detect overfitting. The typical practises covered in today's post will assist you in understanding how to deal with overfitting in model training.
Learn more about SKY ENGINE AI offering
To get more information on synthetic data, tools, methods, technology check out the following resources:
- Telecommunication equipment AI-driven detection using drones
- A talk on Ray tracing for Deep Learning to generate synthetic data at GTC 2020 by Jakub Pietrzak, CTO SKY ENGINE AI (Free registration required)
- Example synthetic data videos generated in SKY ENGINE AI platform to accelerate AI models training
- Presentation on using synthetic data for building 5G network performance optimization platform
- Working example with code for synthetic data generation and AI models training for team-based sport analytics in SKY ENGINE AI platform


